在当今数字化时代,人工智能、机器学习与深度学习构成了现代智能技术的核心支柱。理解它们的关系,掌握如智能分类与IK分词器这样的具体工具,是进行人工智能应用软件开发的关键。
一、人工智能、机器学习与深度学习:层次递进的关系
这三者并非并列概念,而是一种从宏观到微观、从目标到方法的包含与递进关系。
1. 人工智能:这是最广阔的概念,旨在让机器模拟或实现人类的智能行为,如学习、推理、感知和决策。它是终极目标。
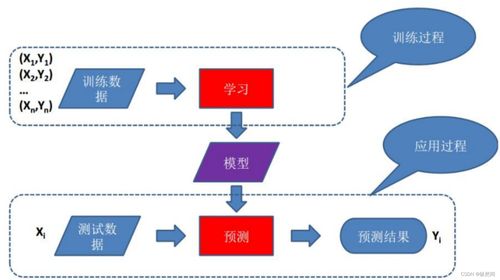
2. 机器学习:是实现人工智能的核心途径与子集。它不依赖显式编程,而是通过算法让计算机从数据中自动“学习”规律和模式,并做出预测或判断。
3. 深度学习:是机器学习的一个子领域和强大分支。它模仿人脑的神经网络结构,通过多层的“深度”神经网络来处理数据,特别擅长处理图像、语音、文本等非结构化数据。
简言之,人工智能 > 机器学习 > 深度学习。深度学习推动了当前AI浪潮,但机器学习还包括其他算法(如决策树、支持向量机),而AI的范畴则更广。
二、智能分类任务的典型执行流程
以文本分类(如新闻分类、情感分析)为例,一个典型的智能分类流程包含以下步骤:
- 问题定义与数据收集:明确分类目标(如区分体育新闻和财经新闻),并收集大量已标注的样本数据。
- 数据预处理与特征工程:对原始文本数据进行清洗(去噪声、标准化),并转化为机器可理解的特征。这通常涉及分词(下文详述)、去除停用词、词干提取等。特征可以是词频、TF-IDF值,或词向量(Word2Vec, BERT等)。
- 模型选择与训练:根据任务特点选择合适的机器学习或深度学习模型(如朴素贝叶斯、逻辑回归、卷积神经网络CNN或循环神经网络RNN)。使用训练集数据对模型进行训练,使其学习特征与类别标签之间的映射关系。
- 模型评估与优化:使用独立的验证集或测试集评估模型性能(准确率、精确率、召回率等)。根据结果调整模型参数、优化特征或尝试其他模型,这是一个迭代过程。
- 部署与应用:将训练好的模型集成到应用软件中,接受新的未标注数据输入,并输出分类结果。
三、IK分词器在文本处理中的使用
在中文文本处理(如上述分类流程的第二步)中,分词是基础且关键的一步。IK Analyzer(IK分词器)是一个广泛应用的中文分词工具包。
- 核心功能:它将连续的中文序列切分成一个个独立的、有意义的词条(Tokenization),支持智能细粒度切分和最粗粒度切分两种模式,并能过滤停用词。
- 基本使用流程(以Java为例):
- 引入依赖:在项目中添加IK Analyzer的JAR包。
- 初始化:创建
IKAnalyzer对象。
- 分词处理:使用分析器对输入文本进行分词,得到词元(Token)流。
- 结果获取:遍历词元流,获取每一个分词结果及其属性。
- 扩展词典:IK分词器允许用户扩展自定义词典(如专业术语、新热词),以提升分词的准确性,这对于特定领域(如医疗、金融)的应用至关重要。
四、人工智能应用软件开发的整合实践
开发一款AI应用软件,就是将上述理论和技术流程工程化的过程:
- 需求分析与技术选型:明确软件要解决的AI问题(分类、推荐、识别等),据此选择合适的技术栈(如基于Python的Scikit-learn/TensorFlow/PyTorch框架,结合Java/Go等业务语言)。
- 数据处理管道构建:集成像IK分词器这样的预处理工具,构建自动化、可复用的数据清洗和特征提取流水线。
- 模型服务化:将训练好的模型封装成独立的、可通过API(如RESTful API)调用的服务(例如使用TensorFlow Serving、Flask或FastAPI),实现与业务逻辑的解耦。
- 系统集成与部署:将模型服务、业务逻辑、用户界面等模块集成,并部署到服务器或云平台,考虑性能、并发和 scalability。
- 持续迭代与监控:上线后持续收集新数据,监控模型性能衰减,并定期重新训练和更新模型,形成闭环。
从理解AI、ML、DL的底层关系,到掌握智能分类等任务的通用流程,再到熟练运用IK分词器等具体工具,最终整合成稳健的应用程序,构成了人工智能应用软件开发的完整知识链路与实践路径。开发者需要兼具算法理解力与工程实现能力,方能将智能技术转化为实际价值。